上一篇介绍了Stream提供的接口,大部分接口在其它语言中都有对应概念,不过Collector这个概念是自己之前未曾接触过的,因此这里再来看看Java 8里的Collector是如何使用的。
Collector接口定义
Collector接口定义并不复杂,
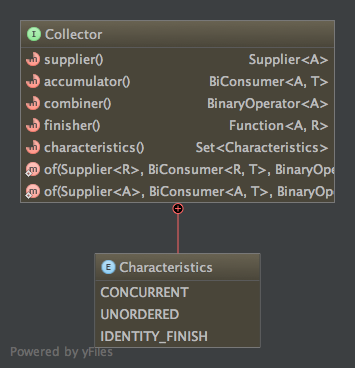
其主要由supplier、accumulator、cimbiner、finisher构成。Java 8自带了哪些Collector实现,在Collectors类中可以找寻到。
Collectors代码示例
与上一篇一样,一一试用Collectors提供的各函数。
- averagingInt/averagingLong/averagingDouble,计算平均值
Stream.of(1, 2, 3).collect(Collectors.averagingInt(x -> x))
- counting,统计数目
Stream.of(1, 1, 2, 3, 5).collect(Collectors.counting());
- maxBy,获取最大元素
Stream.of(1, 2, 3, 4, 5).collect(Collectors.maxBy((x, y) -> x - y)).ifPresent(System.out::println);
- minBy,获取最小元素
Stream.of(1, 2, 3, 4, 5).collect(Collectors.minBy((x, y) -> x - y)).ifPresent(System.out::println);
- summingInt/summingLong/summingDouble
Stream.of(1, 2, 3, 4, 5).collect(Collectors.summingInt(x -> x));
Stream.of(1, 2, 3, 4, 5).collect(Collectors.summingLong(x -> x));
Stream.of(1, 2, 3, 4, 5).collect(Collectors.summingDouble(x -> x));
- summarizingInt/summarizingLong/summarizingDouble
IntSummaryStatistics statistics = Stream.of(1, 2, 3).collect(Collectors.summarizingInt(x -> x));
System.out.println(statistics);
- joining,拼接Stream中元素
Stream<String> stream = Stream.of("hello", "world");
stream.collect(Collectors.joining();
Stream<String> stream = Stream.of("hello", "world");
stream.collect(Collectors.joining(", "));
Stream<String> stream = Stream.of("hello", "world");
stream.collect(Collectors.joining(", ", "prefix, ", ", suffix"));
- toList,将Stream转化成List,实际类型是ArrayList
Stream.of(1, 2, 3, 4, 5).collect(Collectors.toList());
- toSet,将Stream转化成Set,实际类型是HashSet
Stream.of(1, 2, 3, 4, 5).collect(Collectors.toSet());
- toMap,将Stream转化成Map,实际类型是HashMap
Stream.of(1, 2, 3, 4, 5).collect(Collectors.toMap(x -> x, x -> x * x))
- toConcurrentMap,将Stream转化为ConcurrentHashMap
Stream.of(1, 2, 3, 4, 5).collect(Collectors.toConcurrentMap(x -> x, x -> x * x))
- toCollection,将Stream转化为指定类型的容器,通过提供supplier来实现
Stream.of(1, 2, 3).collect(Collectors.toCollection(TreeSet::new));
- collectingAndThen,在传入的Collector基础之上再执行一个finisher操作
Stream.of(1, 2, 3).collect(Collectors.collectingAndThen(Collectors.averagingInt(x -> x), x -> x.intValue()));
- mapping, 适配一个已有的Collector,对Stream中元素执行mapper操作后再进行处理
Stream<String> stream = Stream.of("hello", "world");
stream.collect(Collectors.mapping(x -> x.length(), Collectors.toList()));
- reducing,执行reduce操作
Stream.of(1, 2, 3).collect(Collectors.reducing((x, y) -> x + y)).ifPresent(System.out::println);
- groupingBy,对Stream中元素进行分组
public class Java8 {
public static class Sample {
public int score;
public int type;
public Sample(int score, int type) {
this.type = type;
this.score = score;
}
@Override
public String toString() {
return "Sample{" +
"score=" + score +
", type=" + type +
'}';
}
}
public static void main(String[] args) throws Exception {
List<Sample> samples = Arrays.asList(
new Sample(90, 1),
new Sample(80, 1),
new Sample(80, 1),
new Sample(70, 2),
new Sample(60, 2),
new Sample(50, 3));
// 简单分组
// {1=[Sample{score=90, type=1}, Sample{score=80, type=1}, Sample{score=80, type=1}], 2=[Sample{score=70, type=2}, Sample{score=60, type=2}], 3=[Sample{score=50, type=3}]}
Map<Integer, List<Sample>> one = samples.stream().collect(Collectors.groupingBy(x -> x.type));
System.out.println(one);
// 二级分组,先按类别分组,再按分数分组
// {1={80=[Sample{score=80, type=1}, Sample{score=80, type=1}], 90=[Sample{score=90, type=1}]}, 2={70=[Sample{score=70, type=2}], 60=[Sample{score=60, type=2}]}, 3={50=[Sample{score=50, type=3}]}}
Map<Integer, Map<Integer, List<Sample>>> second = samples.stream().collect(Collectors.groupingBy(x -> x.type, Collectors.groupingBy(x -> x.score)));
System.out.println(second);
// 配合其余Collectors里的接口使用
// 分组后求和
// {1=250, 2=130, 3=50}
Map<Integer, Integer> third = samples.stream().collect(Collectors.groupingBy(x -> x.type, Collectors.summingInt(x -> x.score)));
System.out.println(third);
// 分组后获取最大值
// {1=Optional[Sample{score=90, type=1}], 2=Optional[Sample{score=70, type=2}], 3=Optional[Sample{score=50, type=3}]}
Map<Integer, Optional<Sample>> forth = samples.stream().collect(Collectors.groupingBy(x -> x.type, Collectors.maxBy((x, y) -> x.score - y.score)));
System.out.println(forth);
// 分组后reduce
// {1=Optional[250], 2=Optional[130], 3=Optional[50]}
Map<Integer, Optional<Integer>> fifth = samples.stream().collect(Collectors.groupingBy(x -> x.type, Collectors.mapping(x -> x.score, Collectors.reducing((x, y) -> x + y))));
System.out.println(fifth);
}
}
- partitioningBy,特殊的分组,将Stream元素分成true、false两组,其余支持的操作同groupingBy
// 分成true/false两组
// {false=[Sample{score=70, type=2}, Sample{score=60, type=2}, Sample{score=50, type=3}], true=[Sample{score=90, type=1}, Sample{score=80, type=1}, Sample{score=80, type=1}]}
Map<Boolean, List<Sample>> sixth = samples.stream().collect(Collectors.partitioningBy(x -> x.type == 1));
System.out.println(sixth);
总结
Collectors里提供了不少功能,特别是groupingBy与其它接口的组合使用,可以实现一些复杂的数据处理与统计需求。有那么一点Linq的意思。不过在真正应用了groupingBy之后,觉得这种实现方式未必比以前直白繁琐的方式强,也许在实际项目中应用之后会有不同的体会。